更新了文档 |
2 years ago | |
|---|---|---|
| best-practice | 2 years ago | |
| database | 2 years ago | |
| dev-protocol-common | 2 years ago | |
| dev-protocol-design-pattern | 2 years ago | |
| dev-protocol-devops | 3 years ago | |
| dev-protocol-drools | 2 years ago | |
| dev-protocol-extend | 3 years ago | |
| dev-protocol-gateway | 3 years ago | |
| dev-protocol-log | 2 years ago | |
| dev-protocol-pay | 2 years ago | |
| dev-protocol-shardingtask | 3 years ago | |
| dev-protocol-springboot | 2 years ago | |
| dev-protocol-test | 3 years ago | |
| dev-protocol-tools | 2 years ago | |
| jpa | 3 years ago | |
| longpolling/demo/demo1 | 2 years ago | |
| utils/dev-protocol-id | 2 years ago | |
| .gitignore | 3 years ago | |
| README.md | 2 years ago | |
| pom.xml | 2 years ago | |
README.md
百业代码规范及一些标准化过程示例 v0.1.1
0. 项目说明
对后端java代码进行一些标准化的过程说明,帮助整个技术团队提升自己的技术规范及水平
1. 项目内容说明
dev-protocol-test
- SpringBoot项目Test的编写规范及使用标准
- 参考: https://mp.weixin.qq.com/s/W5v8zOCHbc2_NvobMGaU8w dev-protocol-log
- 分布式日志系统的设计及实现,主要涉及kafka Springboot ELK dev-protocol-gateway
- 智能网关设计 dev-protocol-devops
- DevOps 相关的最佳实现 dev-protocol-shardingtask
- 配置多数据源和分表分库实现
1.1 基本命令(dev-protocol-log)
- Kafka 查看topic列表命令(连接其中一个就好了): 【旧版】kafka-topics.sh --zookeeper 172.16.26.183:2181 --list 【新版】kafka-topics.sh --bootstrap-server 172.16.26.183:9092 --list (– zookeeper is not a recognized option主要原因是 Kafka 版本过高,命令不存在) 创建topic主题 kafka-topics.sh --bootstrap-server 172.16.26.183:9092 --create --topic topic1 --partitions 1 --replication-factor 3 --create 命令后 --topic 为创建topic 并指定 topic name --partitions 为指定分区数量 --replication-factor 为指定副本集数量 向kafka集群发送数据 【无key型消息】kafka-console-producer.sh --bootstrap-server 172.16.26.183:9092 --topic topic1 【有key型消息】 kafka-console-producer.sh --bootstrap-server 172.16.26.183:9092 --topic topic1 --property parse.key=true (默认消息键与消息值间使用“Tab键”进行分隔,切勿使用转义字符(\t)) kafka命令接受数据 kafka-console-consumer.sh --bootstrap-server 172.16.26.183:9092 --topic topic1 --from-beginning kafka查看消费进度:(当我们需要查看一个消费者组的消费进度时,则使用下面的命令)(启动Consumer的时候才会真的生效)【这条命令对查询消费特别重要】 kafka-consumer-groups.sh --bootstrap-server 172.16.26.183:9092 --describe --group group1
1.2 注意事项(dev-protocol-log)
一致性确定 命令中的 --bootstrap-server 和配置文件中的要一致
允许外部端口连接
listeners=PLAINTEXT://0.0.0.0:9092
外部代理地址
advertised.listeners=PLAINTEXT://121.201.64.12:9092 https://blog.csdn.net/pbrlovejava/article/details/103451302 国内下载镜像加速 https://www.newbe.pro/
1.3 海量日志收集架构设计(dev-protocol-log)
- 海量日志收集架构示意图
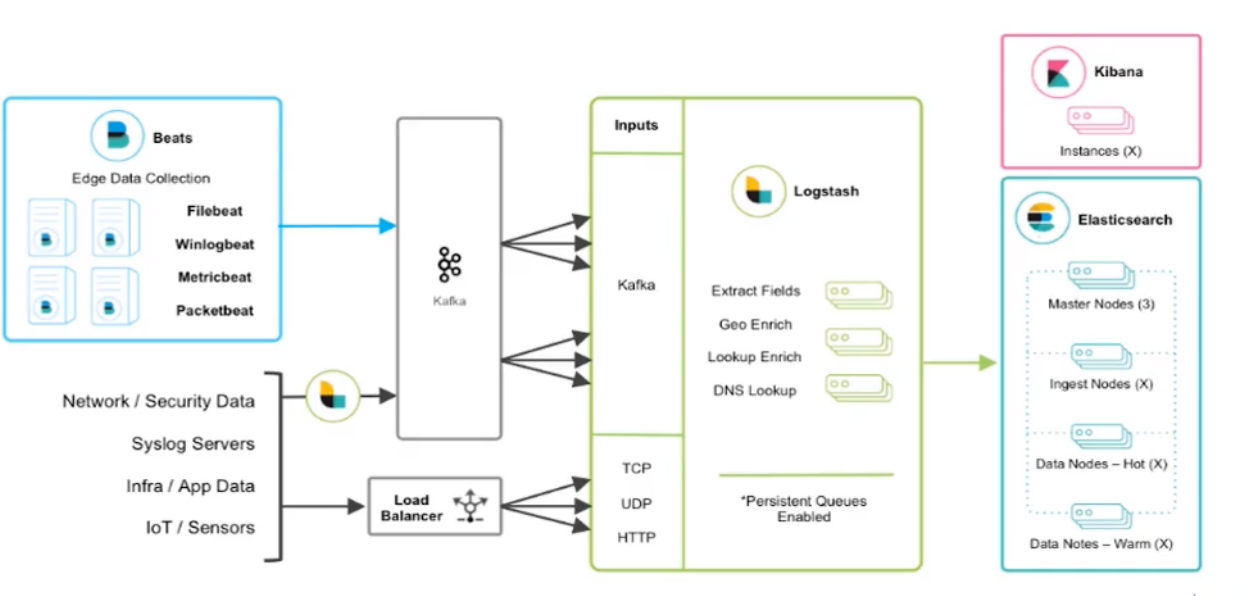
- 标准架构(海量): Beats(日志收集) -> kafka(日志堆积) -> Logstash(日志过滤) -> ElasticSearch(日志查询) -> Kibana(效果展示)
- 简化收集方案1: 直接使用Log4j的插件和Logstash集成 -> ElasticSearch(日志查询) -> Kibana(效果展示)
- 简化收集方案2: 使用Log4j自己封装一个appender -> ElasticSearch(日志查询) -> Kibana(效果展示)
- 简化收集方案3: 直接使用kafka的appender(log4j提供的),直接实现 -> kafka(日志堆积) -> ElasticSearch(日志查询) -> Kibana(效果展示)
- 先进技术: SkyWalking 的 Netty或者Agent的方式,直接传到另外一个Agent端
- 实际落地架构图
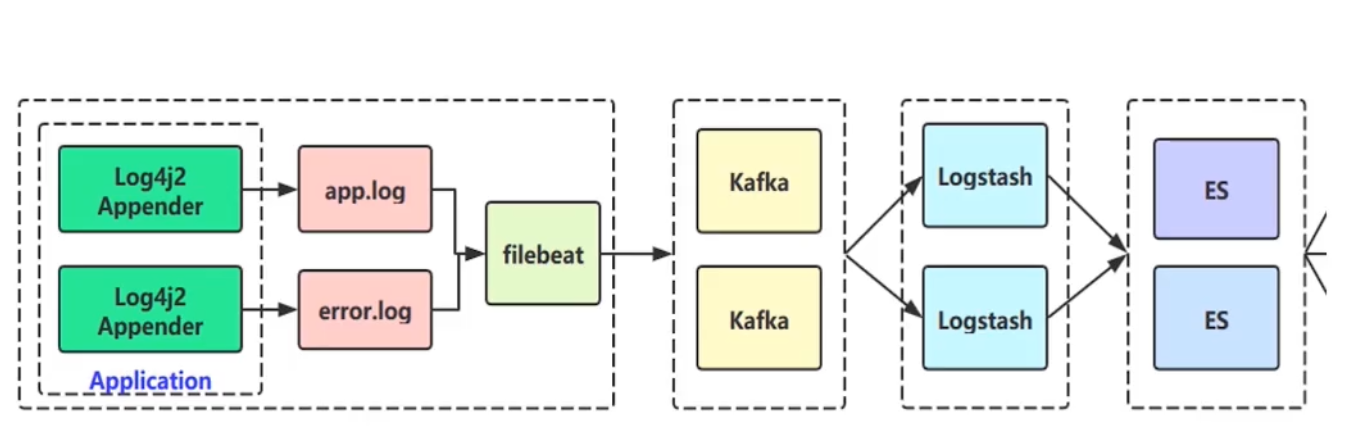
- 全域日志收集架构落地图
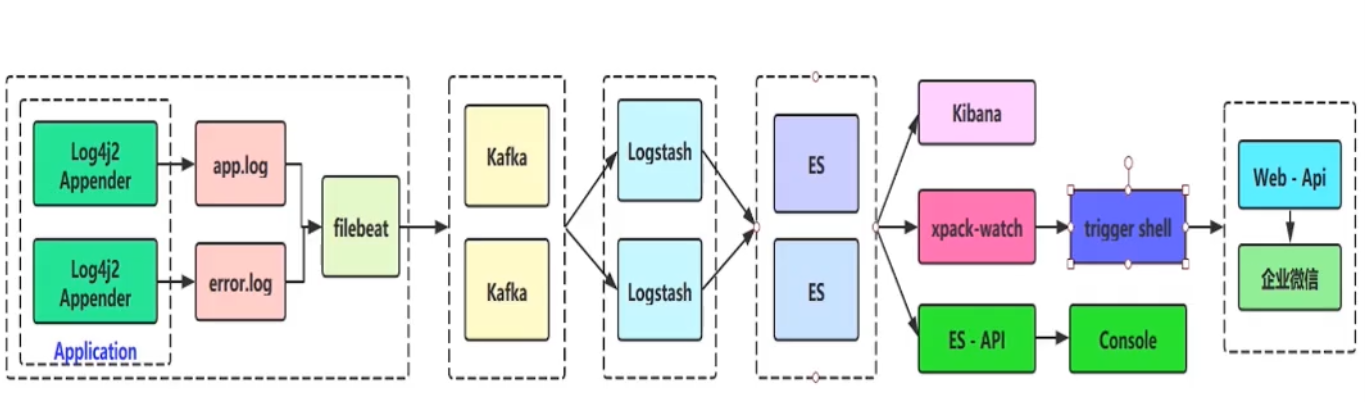
1.4 日志输出设计
-
- 使用 Log4j2 的相关技术进行日志定义
- 使用 Log4j2 的相关技术进行日志定义
-
- 使用 filebeat 进行日志的收集
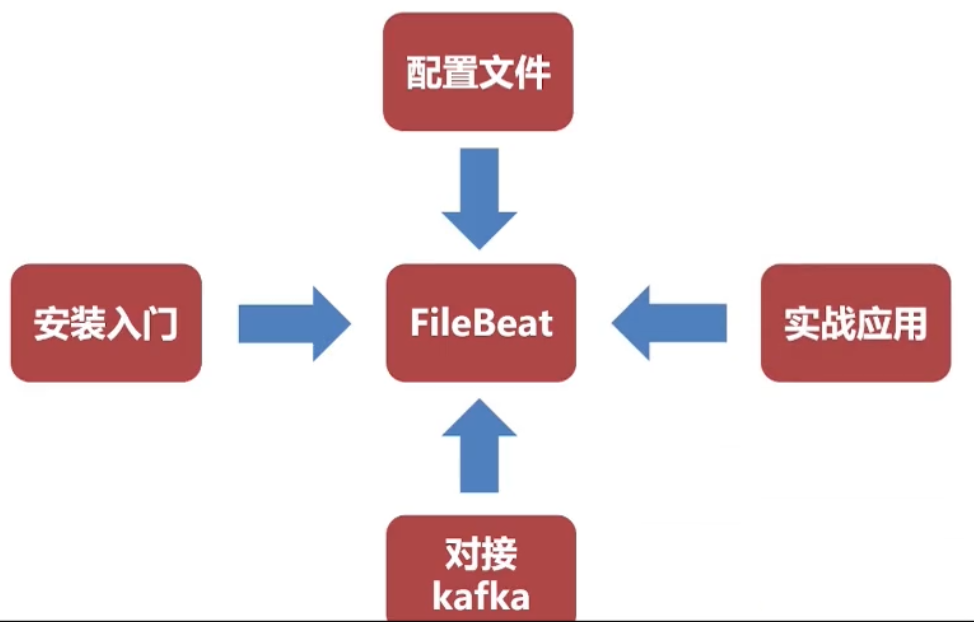
启动前先进行检查 ./filebeat -c 配置文件.yml -configtest 启动顺序 kafka -> 自己的应用程序 -> filebeat
- 使用 filebeat 进行日志的收集
3.1 智能网关
JWT 在微服务架构下的认证过程
-
A> 服务器自主验签方式
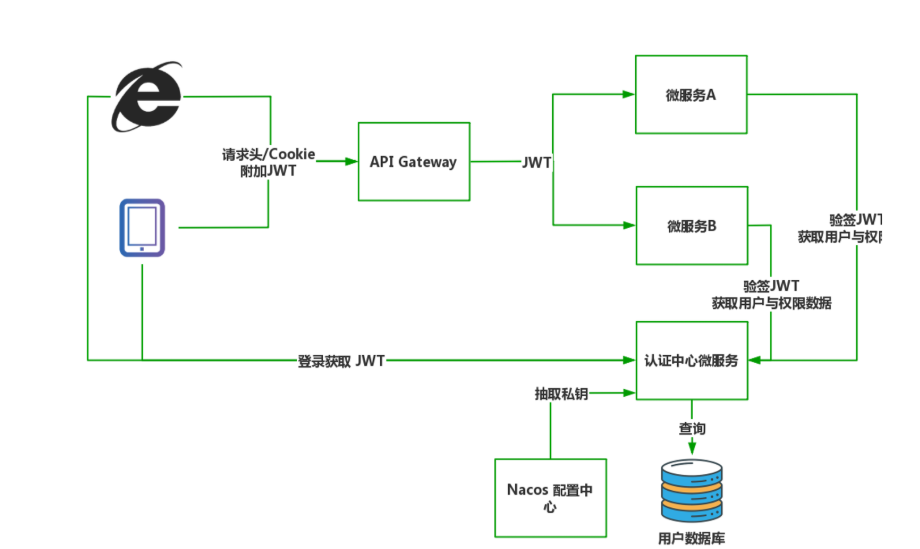
- 第一步,认证中心微服务负责用户认证任务,在启动时从 Nacos 配置中心抽取 JWT 加密用私钥
- 第二步,用户在登录页输入用户名密码,客户端向认证中心服务发起认证请求
- 第三步,认证中心服务根据输入在用户数据库中进行认证校验,如果校验成功则返回认证中心将生成用户的JSON数据并创建对应的 JWT 返回给客户端
- 第四步,在收到 JSON 数据后,客户端将其中 token 数据保存在 cookie 或者本地缓存中
- 第五步,随后客户端向具体某个微服务发起新地请求,这个 JWT 都会附加在请求头或者 cookie 中发往 API 网关,网关根据路由规则将请求与jwt数据转发至具体的微服务。中间过程网关不对 JWT 做任何处理
- 第六步,微服务接收到请求后,发现请求附带 JWT 数据,于是将 JWT 再次转发给用户认证服务,此时用户认证服务对 JWT 进行验签,验签成功提取其中用户编号,查询用户认证与授权的详细数据
- 第七步,具体的微服务收到上述 JSON 后,对当前执行的操作进行判断,检查是否拥有执行权限,权限检查通过执行业务代码,权限检查失败返回错误响应
-
B> API 网关统一验签方案
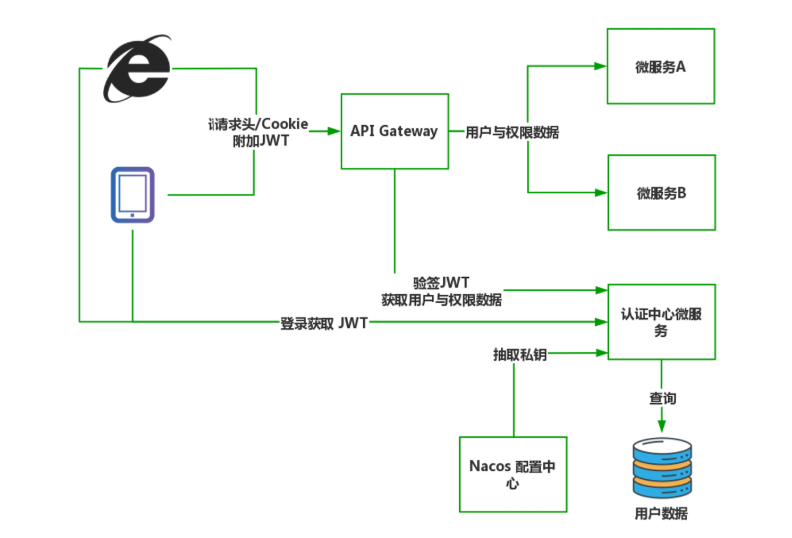 API 网关统一验签与服务端验签最大的区别是在 API 网关层面就发起 JWT 的验签请求,之后路由过程中附加的是从认证中心返回的用户与权限数据,其他的操作步骤与方案一是完全相同的
API 网关统一验签与服务端验签最大的区别是在 API 网关层面就发起 JWT 的验签请求,之后路由过程中附加的是从认证中心返回的用户与权限数据,其他的操作步骤与方案一是完全相同的
TODO-List
- 使用 切面+注解 的方式对同一类的请求带上相对应的验证信息
- 注意在调用请求的时候要对内部鉴权方式和外部鉴权方式进行区分,然后知道在使用JWT方案的时候要进行JWT防止伪造鉴定
- Nginx相关的配置
JPA审计
建议使用源码
dev-protocol-jpaauditing1 (自定义审计) dev-protocol-jpaauditing2 (内部代码实现方式) dev-protocol-jpaauditing3 (正式环境使用)
原理分析
-
从 @EnableJpaAuditing 入手分析
- package org.springframework.data.jpa.repository.config;
- @Import(JpaAuditingRegistrar.class)
Auditing 这套封装是 Spring Data JPA 实现的,而不是 Java Persistence API 规定的 注解里面还有一项重要功能就是 @Import(JpaAuditingRegistrar.class) 这个类,它帮我们处理 Auditing 的逻辑。
步入 org.springframework.data.jpa.repository.config.JpaAuditingRegistrar.registerBeanDefinitions 方法
- super.registerBeanDefinitions(annotationMetadata, registry);
- registerInfrastructureBeanWithId(...);
- 打开 AuditingEntityListener 的源码
- AuditingEntityListener 的实现还是比较简单的,利用了 Java Persistence API 里面的@PrePersist、@PreUpdate 回调函数, 在更新和创建之前通过AuditingHandler 添加了用户信息和时间信息
原理分析结论
- 查看 Auditing 的实现源码,其实给我们提供了一个思路,就是怎么利用 @PrePersist、@PreUpdate 等回调函数和 @EntityListeners 定义自己的框架代码。这是值得我们学习和参考的,比如说 Auditing 的操作日志场景等。
- 想成功配置 Auditing 功能,必须将 @EnableJpaAuditing 和 @EntityListeners(AuditingEntityListener.class) 一起使用才有效。
- 我们是不是可以不通过 Spring data JPA 给我们提供的 Auditing 功能,而是直接使用 @PrePersist、@PreUpdate 回调函数注解在实体上, 也可以达到同样的效果呢?答案是肯定的,因为回调函数是实现的本质。
整理
使用相对应的注解去注册进Spring容器 使用注册的回调函数进行注解化设置
正确使用 @Entity 里面的回调方法
概念掌握
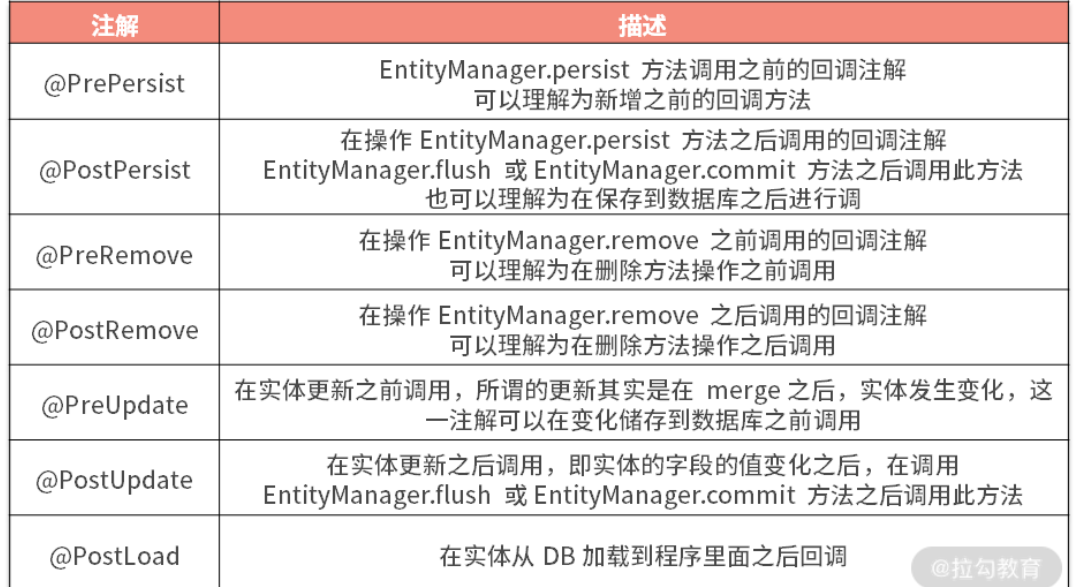
Java Persistence API 里面规定的回调方法有哪些?
回调事件注解表
- 注意事项
- 回调函数都是和 EntityManager.flush 或 EntityManager.commit 在同一个线程里面执行的,只不过调用方法有先后之分, 都是同步调用,所以当任何一个回调方法里面发生异常,都会触发事务进行回滚,而不会触发事务提交。
- Callbacks 注解可以放在实体里面,可以放在 super-class 里面,也可以定义在 entity 的 listener 里面,但需要注意的是: 放在实体(或者 super-class)里面的方法,签名格式为“void ()”,即没有参数,方法里面操作的是 this 对象自己; 放在实体的 EntityListener 里面的方法签名格式为“void (Object)”,也就是方法可以有参数,参数是代表用来接收回调方法的实体。
- Callbacks 注解可以放在实体里面,可以放在 super-class 里面,也可以定义在 entity 的 listener 里面, 但需要注意的是:放在实体(或者 super-class)里面的方法,签名格式为“void ()”,即没有参数,方法里面操作的是 this 对象自己; 放在实体的 EntityListener 里面的方法签名格式为“void (Object)”,也就是方法可以有参数,参数是代表用来接收回调方法的实体。
- JPA Callbacks 的使用方法
- 修改 BaseEntity,在里面新增回调函数和注解
使用总结
在实体中定义一些通用逻辑, 然后在对应 Listener中进行调用时机指定 (参数的合理化和健壮性检测) JPA Callbacks 的实现原理,事件机制