You cannot select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
2.2 KiB
2.2 KiB
ID生成策略
单体生成ID策略
- 借助工具类进行实现
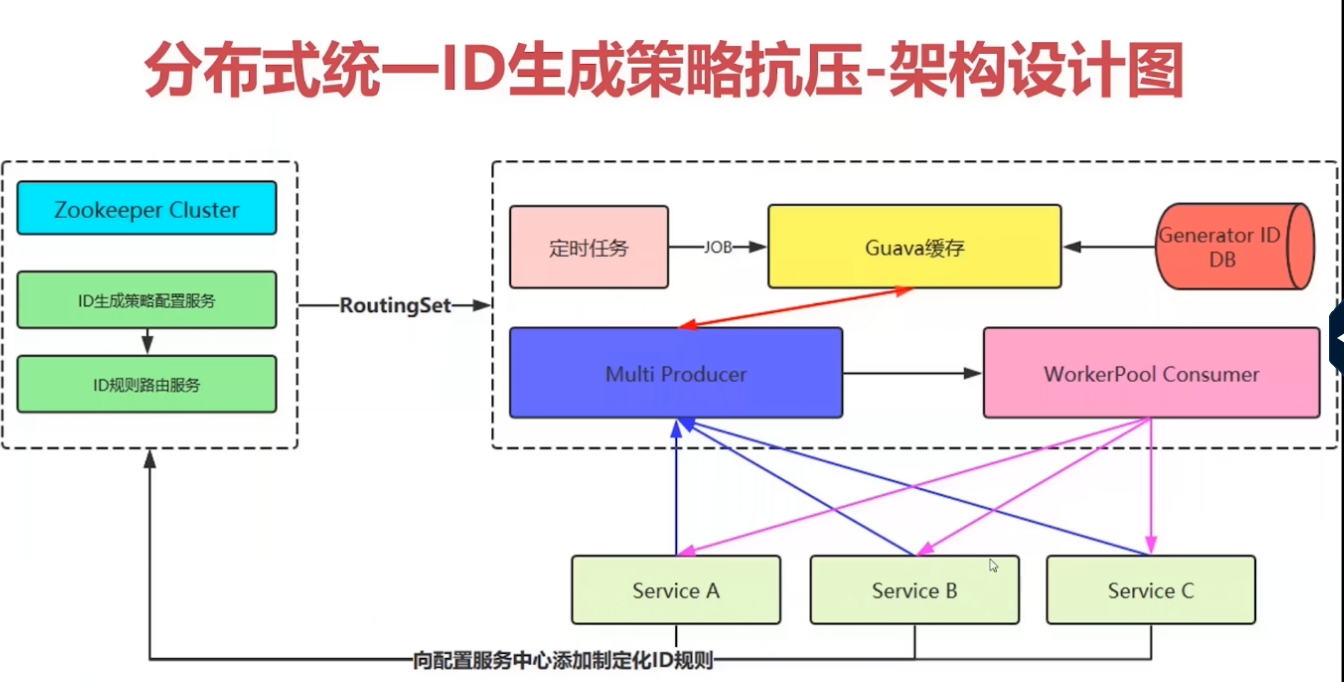
分布式式统一ID生成策略抗压
- 业务ID生成方式
- 最使用带有业务含义的ID生成策略,这种方式在传统应用系统,特定的场景下非常好用。比如我们有一张商品表,这张表的数据维度是这样的,比如是按照城市和区域来划分的。
- 前缀6位为城市和区域的方式进行组织,后面可以拼接一个简单的32位UUID字符串
- 查询一个城市下的数据SQL
- SELECT * FROM goods_shelf gs where id > '100010000000000000000000000000000' and id < '2000000000000000000000000000000000';
- 对业务分类特征明显的情况, 对查询场景优化, ID的设计会显得格外的重要, 充分利用ID索引
- 前面的必须为数字,后面的可以是随机字母加数字,不影响查询
- 高并发统一ID生成服务
- 考虑问题:
- 如何解决ID生成在并发下的重复生成问题?
- 如何承载高并发ID生成的性能瓶颈问题?
- 业界错误实现:
- 使用Zookeeper的分布式锁实现,Zookeeper在上千的写场景下会出现性能瓶颈
- 使用Redis缓存,利用Redis分布式锁实现,超时重试场景下对性能有很大的问题
- 业界主流的分布式高并发ID生成规则方案
- 实现1:提前加载, 也就是预加载的机制
- 实现2:单点生成方式
- 预加载的核心:
- 提前加载,也就是预加载的机制(内存中即可),获取到阈值的时候,然后去生成一批新的
- 并发的获取,采用Disruptor框架去提升性能
- 单点生成核心:
- 固定的机器节点来生成一个唯一的ID,好处是能做到全局唯一,可以把所用的服务机器上配置一个服务
- 需要相应的业务规则拼接:机器码 + 时间戳 + 自增序列
- 解决NTP问题,时间服务器同步的问题
- NTP问题
- 网络时间协议,它是同来同步网络中各个计算机的时间的协议
- 总之就是本地的时间校准可能会存在回到过去的可能
- 后面再加一个自增的序列,保证单点下永远会自增
- 考虑问题:
架构设计图